Traces are the new source code.
The unit of work is no longer the diff. It is the session you ran to produce it. Every prompt, tool call, and edit is behind the outcome.
opentraces is a local-first evidence layer for agent work, capturing what the agent sees, does, and changes.
hub previewnew ─────────────────────────────
Every run your team makes is data you can learn from. The Hub is the web companion to the CLI, where your shared bucket, trails, context tree, and datasets become browsable, with trace intelligence on top.
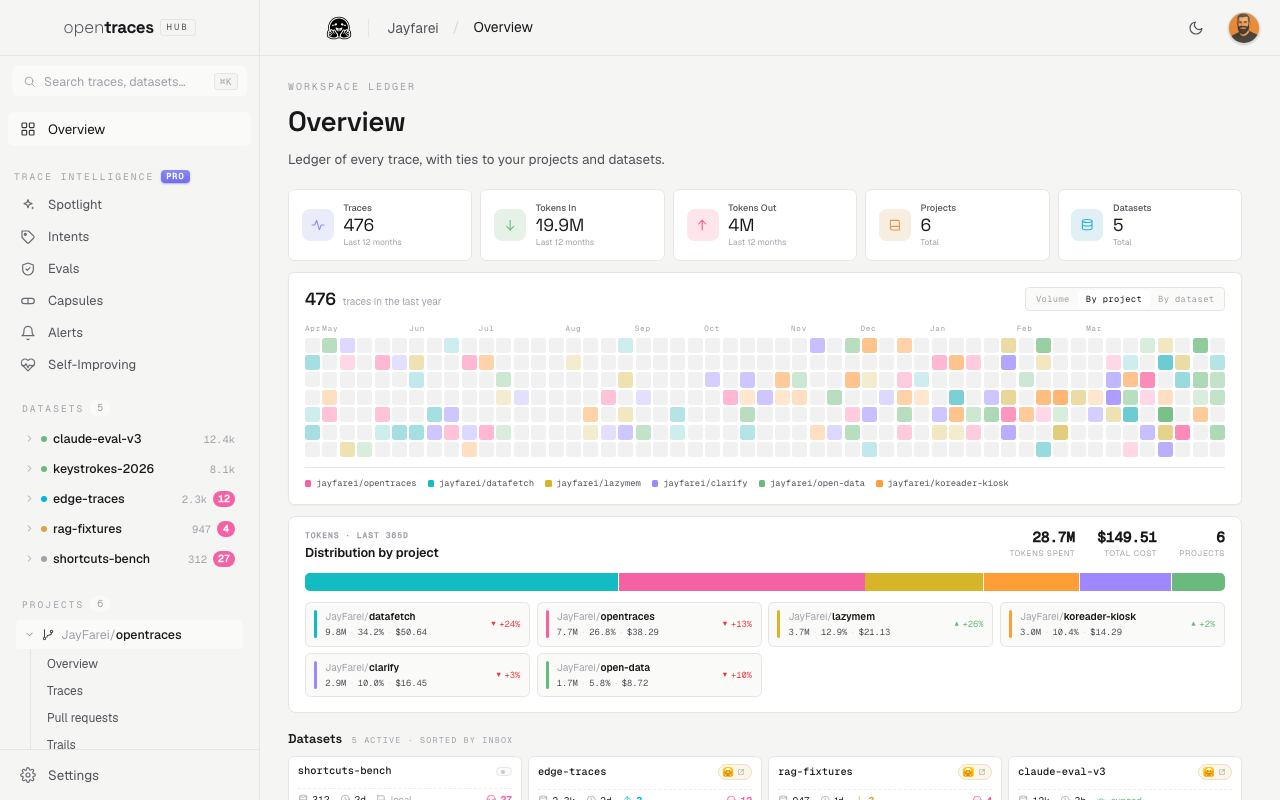
features ────────────────────────────────
private trace bucket
Capture-time envelopes, patch history, trail/context companions, blobs, and manifests stay local. Content-hash dedup keeps re-publishing and machine switches safe.
opentraces bucket statustrace discovery
query, skills, map, slice, and get expose deterministic packets over a local lexical + concept index (BM25 plus a bounded concept join, not embeddings), without loading full transcripts.
opentraces trace skillstrace trails
blame commit, blame pr, graph, and track connect each trace patch to the Git history that accepted it, across eight survival states.
opentraces trail blame commitcontext tree
ctx commands reconstruct what the agent saw at a step and produce resume packets.
opentraces ctx treetrace intelligence
Derive-on-demand signals about a run: context waste, run health, and A/B compare of two traces. No LLM, nothing persisted.
opentraces trace map --run-intelworkflow templates
Skill-format packages project raw trace evidence into schema-valid dataset rows for a chosen objective.
opentraces workflow createdataset row review
Approve, reject, reset, schedule, and publish projected rows; raw traces never leave the bucket.
opentraces dataset reviewsecurity tools
Nine detectors, transformers, and a judge run in one fixed order before egress, all explicit and default off.
opentraces security tools listagent-native cli
Structured JSON with next_steps on every command. Built for agents to drive agents.
every command --jsonprivacy & trust ─────────────────────────
Your traces are training data, so cleaning them can’t cost you the signal. Point detectors, transformers, and a judge at exactly the fields that matter, on capture into your bucket and again as you build a training dataset, and decide what runs where.
lineage ─────────────────────────────────
Every change carries the session that made it. Anchor it to the commit that accepted it, follow it through the rebases and reverts after, and you can ask questions git blame can't:
Sum the tokens and wall-clock of every session whose patches ended reverted or lost.
Reverse-blame any file:line back to the session, prompt, and diff behind it.
Walk a bad commit back to its sessions — then fix the process, not just the line.
Filter every session by survival to compile an outcome-labeled dataset.
Behind every answer is one trail — the snapshots and patches in a session, the git anchor that accepted them, and what survived.
Prove it, then improve the process. Show which sessions shipped, which were reverted, and which introduced a bug or left tech debt, and you have the evidence to change what your agents do next — and to label outcome data after the fact. Run the security tools first and the trail itself becomes the label, with no in-session annotation.
how it works ────────────────────────────
Training data is just one use. Once your trace infrastructure is in place, you can leverage it to fuel many more workflows.
Trace Capsule
Share a real usage episode with a third party — attach the actual agent experience to a GitHub issue, not just a summary of the bug.
Skill Evaluation
Keep a versioned dataset of skill usage across traces, build a verifier per skill with the OT SDK, and score whether skill changes improve outcomes.
Standup
A daily report rebuilt from yesterday's sessions: what was attempted, what landed, what failed, and what's still open before you start today.
Spotlight
QMD for agent traces. Search your traces mid-session, outside the loop, or for a handoff, so context travels between sessions without planning ahead.
Alerts
Standing alerts and reports over trace usage: failure rate, context waste, third-party tools, secrets, policy violations, or any pattern you care about.
Intent Pull Request
Walk a PR's commits back to the originating sessions and compile the 'why' alongside the 'how' — intent, lineage, and evidence beside the diff.
get started ─────────────────────────────
Open data is the new open source. Your agent traces are the most valuable dataset nobody is collecting. Nothing leaves your machine until you approve and publish a dataset.